Hadoop 基础之生态圈
前言
本文主要目的是介绍 Hadoop 的基本架构以及衍生出来的各种工具,以期对 Hadoop 有个整体的认识。
Hadoop 生态系统
Hadoop 生态系统是指以 分布式的文件系统 HDFS、分布式的计算框架 MapReduce 以及资源管理器 YARN为基础构成的分布式数据处理系统,其结构图如下图所示:
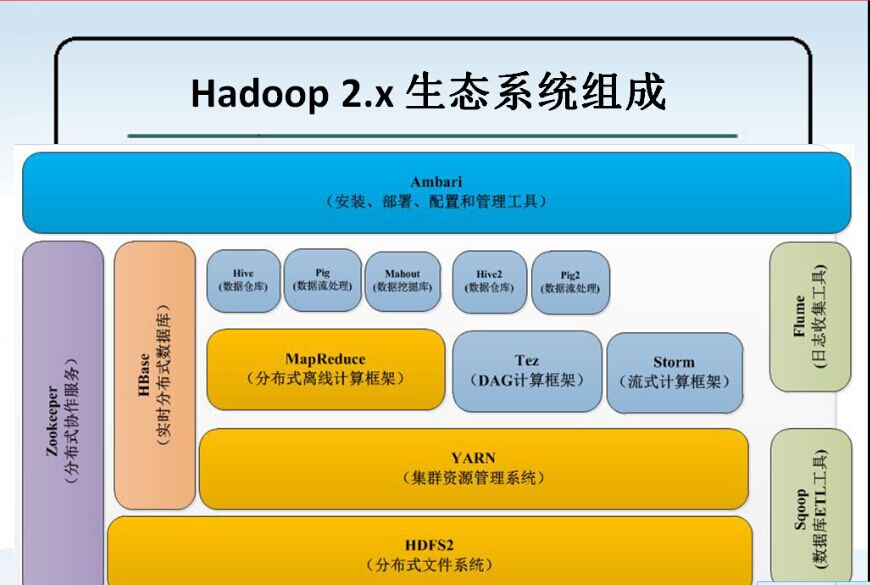
下面将对图中各项组件做一个介绍
HDFS
HDFS 是 Google 于 2003 发表的 分布式文件系统 GFS 论文的开源实现版本,主要目的是使用普通商业电脑解决大量数据的存储以及读取速度问题,在 GFS 出现之前一般主要在单台计算机用 RAID 来提高数据存储量和读取速度。但是采用 RAID 一方面成本比较高(需求太高时可能只有超级计算机才能满足),另一方面数据量过大时可能超级计算机也无法满足需求。所以这个时候就需要采取分布式的方式去满足扩大存储(多台机器多个磁盘)和增加读取速度的需求(多台机器可以同时读)。
MapReduce
MapReduce 是一个分布式的计算框架,在 MapReduce 出现之前就已经有了分布式计算这个概念。但是大多数分布式计算只能专门用于处理一类运算,而 Google 在大量实践中总结出了一个通用的编程模型: map 和 reduce。其中 map 是指分开计算的过程,而 reduce 是指合并结果的过程。而在这一编程模型添加的一系列机制和操作构成了 MapReduce。MapReduce 大大降低了分布式计算的门槛,对于开发人员而言只需要编写一系列 map 和 reduce 函数即可完成所需的分布式计算过程。
YARN
YARN 是一个资源管理框架,主要作用是负责集群的资源调度和作业任务管理。YARN 的出现源于 Hadoop 不能满足统一使用集群资源的需求,因为 Hadoop1 中集群的资源调度和任务管理与 MapReduce 的执行过程是耦合在一起的,而后续出现的 Spark、Storm 等分布式计算系统其架构和执行过程与 MapReduce 不同,无法直接向 Hadoop 申请集群资源。所以为了实现集群资源的统一管理,在 Hadoop2 中对 MapReduce 进行了一个解耦,抽离出了 YARN 这个框架。
ZooKeeper
Zookeeper 主要作用是提供一个分布式、高可用的协调服务,解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Pig
虽然 MapReduce 极大的简化了分布式计算编程的门槛,但是 Yahoo 的工程师依然觉得 MapReduce 编程太过麻烦,所以他们便开发了 Pig 这个脚本语言用于描述对大数据集的操作。这样就可以通过编译 Pig 脚本生成对应的 MapReduce 程序。
Hive
为了方便使用 SQL 的工程师使用 MapReduce,Facebook 的工程师开发了 Hive,通过 Hive 熟悉数据库的工程师可以无门槛的使用 MapReduce。
Mahout
Mahout 的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout 现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。
Tez
Tez 是 Apache 最新开源的支持 DAG 作业的计算框架,它直接源于 MapReduce 框架,核心思想是将 Map 和 Reduce 两个操作进一步拆分,即 Map 被拆分成 Input、Processor、Sort、Merge和Output, Reduce 被拆分成 Input、Shuffle、Sort、Merge、Processor 和 Output 等。
Hase
HBase 是一个建立在 HDFS 之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
Flume
Cloudera 开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
Sqoop
Sqoop 是 SQL-to-Hadoop 的缩写,主要用于传统数据库和 Hadoop 之前传输数据。数据的导入和导出本质上是Mapreduce 程序,充分利用了 MR 的并行化和容错性。
Ambari
Ambari 的作用来说,就是创建、管理、监视 Hadoop 的集群,是为了让 Hadoop 以及相关的大数据软件更容易使用的一个 web 工具。
总结
总的来说 HDFS 、MapReduce 以及 YARN 是 Hadoop 的核心组件,而我们学习 Hadoop 最好从核心组件开始学习其原理机制,再逐渐往上层进行了解。
Thanks
- Hadoop生态圈总结——大数据
- hadoop生态圈各个组件简介
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
- 从0开始学大数据---极客时间