Hadoop 基础之搭建环境
前言
本文主要介绍了 Hadoop 的三种运行模式以及配置的方式。
运行模式
Hadoop 的运行模式分为三种:
- Standalone(本地模式/单机模式/local模式) 该模式下没有任何守护进程,用户程序和 Hadoop 程序运行在同一个 Java 进程,使用的文件系统是本地文件系统而不是分布式文件系统,此模式下一般用于本地调试。
- Pseudo-Distributed(伪集群模式) 在单机上模拟集群模式,各守护进程运行在单独的 Java 进程当中,使用的文件系统是 HDFS
- Fully-Distributed(集群模式) 守护进程运行在集群上,使用的文件系统也是 HDFS
配置过程
本次配置基于 Hadoop2.9.2,其中 Standalone 在 CentOS 7.2 系统下进行配置, Pseudo-Distributed 模式在 MacOS 10.14.4 上进行配置,Fully-Distributed 模式在腾讯云主机上进行配置,集群由两台云主机组成,分别运行 Ubuntu 14.04.1 和 CentOS 7.2 系统。
环境准备
Java 7/8 Hadoop 2.7.x to 2.x 支持 Java 7/8,其它 Hadoop 版本支持的 Java 版本请点击 🔗 进行查询 下载:
1
sudo yum install java-1.8.0-openjdk-devel //centos 安装 Java8,ubuntu 下需要用 apt-get 进行安装
配置环境变量:
1
2
3
4cd ~
vi .bash_profile
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk.i386
source .bash_profilessh 和 rsync: 用
ssh和rsync命令测试后发现 Centos 本身就有,所以无须进行安装。Hadoop
1
2sudo wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
tar -zxvf hadoop-2.9.2.tar.gz这里的下载地址最好根据云主机所在的区域进行选择,如果是国内的云主机最好使用国内的镜像地址,这样下载会快很多。
Standalone 模式
下载解压之后的 Hadoop 默认就是 Standalone 模式,可直接运行 wordcount 进行测试
1 | mkdir input //hadoop 的同级目录创建 |
同时再开一个终端在作业运行的时候输入 jps 查看进程
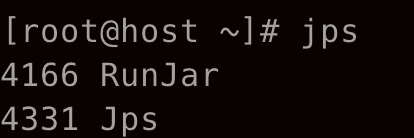
可以看到 Standalone 模式下 Hadoop 只会启动 RunJar 进程来运行整个作业
Pseudo-Distributed 模式
修改 etc/hadoop/core-site.xml
1
2
3
4
5
6
7
8
9
10
11<configuration>
<property>
<name>fs.defaultFS</name> <!--配置访问 nameNode 的 URI-->
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name> <!--指定临时目录,MapReduce 和 HDFS 的许多路径配置依赖此路径-->
<value>/home/hadoop/tmp</value>
</property>
</configuration>修改 etc/hadoop/hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11<configuration>
<property>
<name>dfs.replication</name> <!--配置文件的副本数量-->
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value> <!--关闭防火墙-->
</property>
</configuration>配置免密登录
1
2
3
4ssh localhost 测试能否免密登录(如果能够则跳过以下操作)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys修改 etc/hadoop/hadoop-env.sh(如果提示找不到 JAVA_HOME)
1
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk.i386 //上面配置的 JAVA_HOME 好像没起作用
格式化 HDFS
1
bin/hdfs namenode -format
启动 HDFS
1
sbin/start-dfs.sh
启动后输入 jps 看到以下进程即成功,这个时候可以通过 http://localhost:50070/ 访问 NameNode
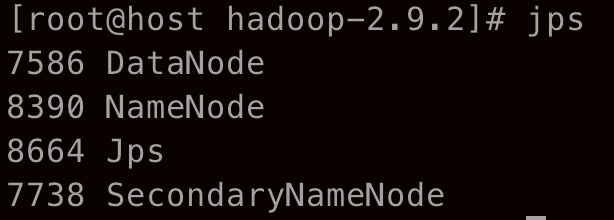
运行 wordcount
1
2
3
4
5
6bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/<username>
bin/hdfs dfs -mkdir /user/<username>/input
bin/hdfs dfs -put LICENSE.txt /user/<username>/input //创建文件夹并上传文件
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount input output //运行 wordcount
bin/hdfs dfs -cat output/part-r-00000 //显示结果在另一终端输入 jps 可以看到运行时的以下进程
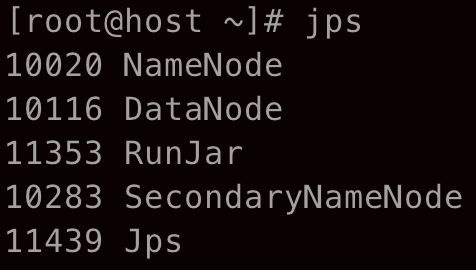
依旧是用 RunJar 提交,只是读取和写入采用了 HDFS。
通过 YARN 执行 Job(可选配置,不过为了更接近真实集群还是建议配置)
修改 etc/hadoop/mapred-site.xml
1
2cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
vi etc/hadoop/mapred-site.xml增加以下内容
1
2
3
4
5
6<configuration>
<property>
<name>mapreduce.framework.name</name> <!--表明运行在 YARN 上-->
<value>yarn</value>
</property>
</configuration>修改 etc/hadoop/yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11<configuration>
<property>
<name>yarn.resourcemanager.hostname</name><!--设置resourcemanager的hostname-->
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name> <!--指定 nodemanager 获取数据的方式-->
<value>mapreduce_shuffle</value>
</property>
</configuration>启动 YARN
1
sbin/start-yarn.sh
启动成功后可以通过 http://localhost:8088/ 访问 ResourceManager 节点,并且输入 jps 会显示以下进程
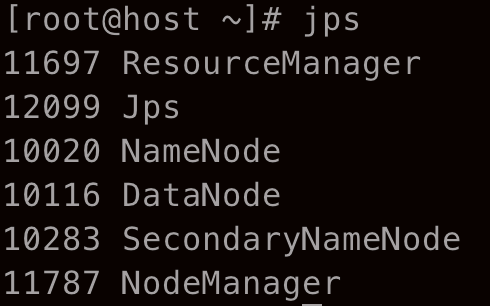
其中 ResourceManager 和 NodeManager 是属于 YARN 的进程。
重复
7的操作,输入 jps 查询进程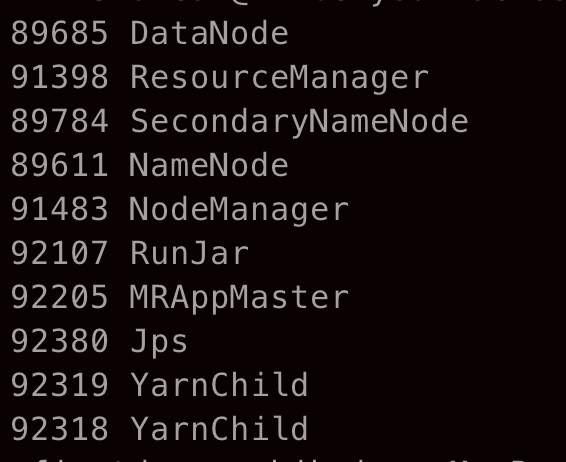
可以看到新增加了 YarnChild 进程和 MRAppMaster 进程,之所以有两个 YarnChild 进程是因为输入文件夹中存在两个文本文件,这说明了 MapReduce 是通过创建多个进程并行计算的。
Fully-Distributed 模式
集群包括两个节点,节点名分别为 master 和 slave,master 和 slave 的节点配置过程基本一致,以下是配置过程(两个节点差异配置会进行注明,建议先配置好 master 节点的 Hadoop,然后用 scp 命令复制到 slave 节点进行修改。):
修改 /etc/hosts
1
2152.136.76.12 master //腾讯云公网ip
94.191.43.137 slave免密登录(⚠️两个节点的登录名必须一致,这里都为 root)
1
2
3
4
5
6
7
8
9master 节点配置本机免密登录以及移动公钥到子节点
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
scp ~/.ssh/id_rsa.pub root@slave:~/
slave 节点配置 master 节点免密登录
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys修改 etc/hadoop/core-site.xml
1
2
3
4
5
6
7
8
9
10
11<configuration>
<property>
<name>fs.defaultFS</name> <!--配置访问 nameNode 的 URI-->
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name> <!--指定临时目录,MapReduce 和 HDFS 的许多路径配置依赖此路径-->
<value>/home/hadoop/tmp</value>
</property>
</configuration>修改 etc/hadoop/hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<configuration>
<property>
<name>dfs.replication</name> <!--配置文件的副本数量-->
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value> <!--关闭防火墙-->
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave:50090</value> <!-- 指定secondarynamenode位置 -->
</property>
</configuration>修改 etc/hadoop/mapred-site.xml
1
2
3
4
5
6<configuration>
<property>
<name>mapreduce.framework.name</name> <!--表明运行在 YARN 上-->
<value>yarn</value>
</property>
</configuration>修改 etc/hadoop/yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11<configuration>
<property>
<name>yarn.resourcemanager.hostname</name><!--设置resourcemanager的hostname-->
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name> <!--指定 nodemanager 获取数据的方式-->
<value>mapreduce_shuffle</value>
</property>
</configuration>修改 etc/hadoop/hadoop-env.sh
1
2export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk.i386 //master 和 slave 填入各自路径
export HADOOP_LOG_DIR=/root/hadoop/hadoop-2.9.2/logs //可以自己选定修改 etc/hadoop/mapred-env.sh
1
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk.i386
修改 etc/hadoop/yarn-env.sh
1
2export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk.i386
export YARN_LOG_DIR=/root/hadoop/hadoop-2.9.2/logs修改 etc/hadoop/slaves
1
2master
slave启动 HDFS 和 YARN
1
2
3bin/hdfs namenode -format //首次运行时格式化
sbin/start-dfs.sh
sbin/start-yarn.sh在 master 和 slave 节点分别输入 jps 后有
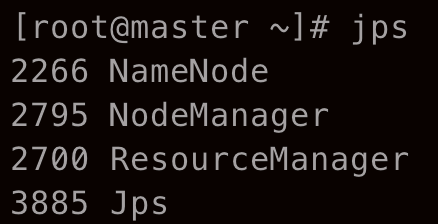
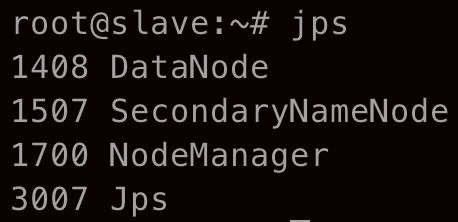
此时可以通过 http://152.136.76.12:8080 (ip 为 master 的公网 ip) 以及 http://152.136.76.12:50070 分别访问 HDFS 的 web 界面和 YARN 的 web 界面,可以看到 HDFS 下有一个 slave 节点,YARN 下有两个节点

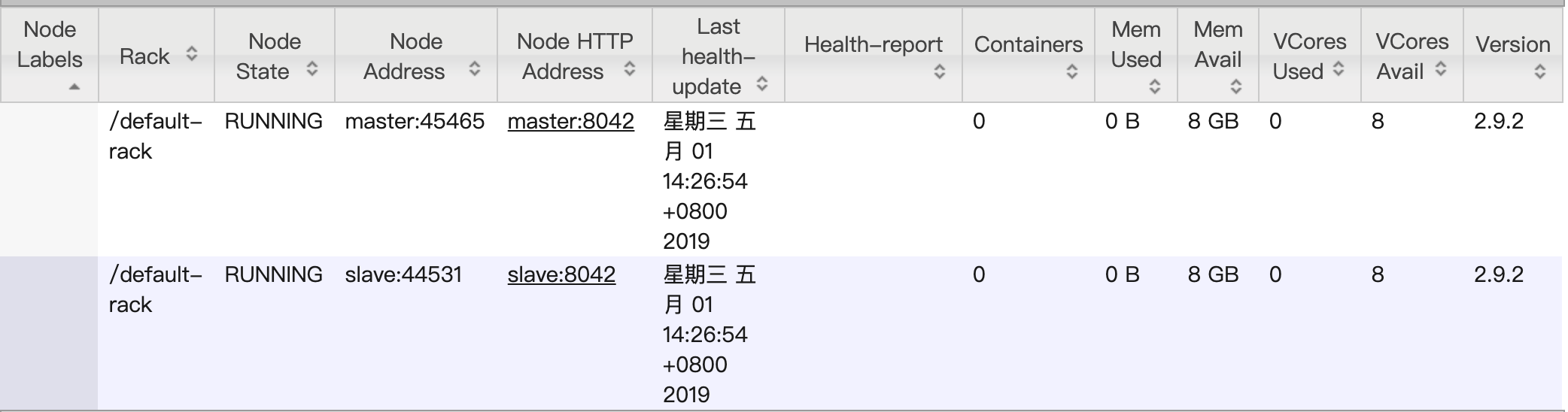
运行 wordcount(与伪分布式中一致)
1
2
3
4
5
6bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/<username>
bin/hdfs dfs -mkdir /user/<username>/input
bin/hdfs dfs -put LICENSE.txt /user/<username>/input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount input output
bin/hdfs dfs -cat output/part-r-00000继续用 jps 查看两台主机的进程
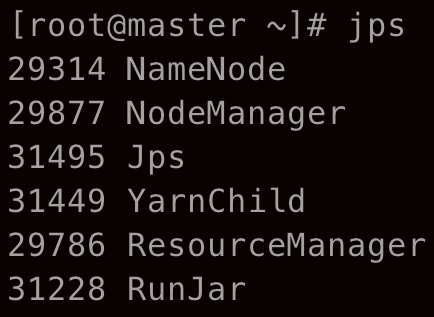
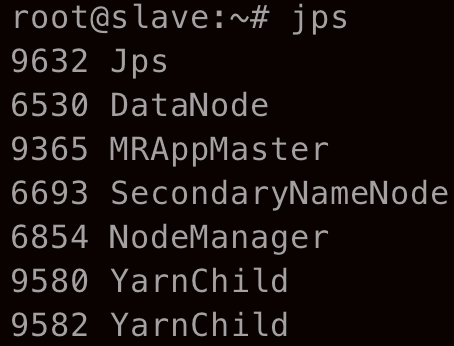
可以看到集群模式中的进程与伪集群模式中的进程没有区别,唯一的区别在于进程在不同的主机上运行。
错误
这里主要记录配置过程中遇到的一部分错误
Container exited with a non-zero exit code 1. Error file: prelaunch.err.
该错误是在腾讯云主机上配置的伪集群模式运行 wordcount 时出现的,尝试了网上的一些办法都没有解决。最后采用自己电脑配置再运行一遍成功,可能是因为云主机的配置问题。
在 YARN 上运行 Java.net.ConnectException: Connection refused
可能是防火墙的原因,根据 🔗 中的提示解决
无法外网访问VM中的 Hadoop YARN 的8088端口
无法通过云主机 ip:8088 访问 YARN 的 Web 页面时,不妨通过
netstat -nlp | grep java查看当前提供 web 服务的端口,如果 ip 是 127.0.0.1 证明存在问题,需要修改 hosts,具体过程见 🔗。slave: bash: line 0: cd: /root/hadoop/hadoop-2.9.2: No such file or directory
配置集群模式时出现,主要原因是手动配置 slave 时 Hadoop 存放路径与 master 不一致,只需要将 slave 的 Hadoop 放在与 master 的同一路径下即可解决。
Thanks
- Hadoop完全分布式部署
- Hadoop三种模式介绍
- hadoop的三种运行模式区别及配置详解