Java 基础之集合框架(一):集合框架
问题
集合类应该是平时使用的非常频繁的类了,但是对其内部构成却一直不太清晰,所以希望通过本篇文章尝试去理解集合框架的整体设计以及集合存在的必要性。在开始分析之前首先让我们思考以下问题:
- 集合存在的意义,集合和数组的区别
- 集合框架的设计意图
- 集合的常用操作
集合存在的意义以及与数组的区别
想要了解 Java 为什么会设计集合,就得先明白集合的出现解决了什么问题,关于这一问题「Java 编程思想」中是这么描述的
如果一个程序中只包含固定数量的且其生命周期都是已知的对象,那么这是一个非常简单的程序。 通常,程序总是根据运行时才知道的某些条件去创建新对象。在此之前,不会知道所需对象的数量,甚至不知道确切的类型。
所以之所以需要集合是因为在编程的过程中会需要保存数量不定、类型不定的数据。
针对数量不定考虑下面这种情况
1 | public class Demo { |
作为一个简单的输入程序,采用数组的形式去保存用户的输入,当用户的输入超过数组可容纳的数量的时候便会抛出异常,这个问题如何解决呢?一种方式是将数组的数量分配的足够大,但是采取这种方式极有可能浪费内存空间。另一种方式则是动态扩展大小,通过动态扩展大小既能够容纳足够多的元素,又能够节约内存空间。而集合正具备动态扩展大小这一特性,所以在这种情况下,集合就体现出了它的作用。 至于类型不定,考虑另一种情况
1 | package com.rookieyang.collections; |
可以看出对于数组而言在动态添加数据会略显麻烦,而且只能保存 String 类型数据,但对于采用集合而言,使用起来不仅简单而且其扩展性也强,我们可以根据自己的需求决定集合中保存何种类型数据,这就实现了代码的复用。 对于集合和数组而言,其主要区别如下
- 数组是静态的,一个数组实例具有固定的大小,集合是动态的,可以根据实际需要动态扩展大小
- 数组既可以保存基本类型,也可保存引用类型,集合只能保存引用类型,在保存基本类型的时候会自动装箱
集合整体框架分析
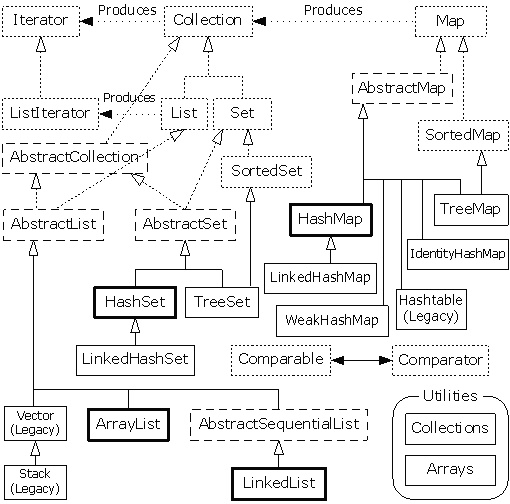
首先看下集合的整体框架图,对于集合而言主要分为两个部分:Collection 和 Map,其中 Collection 主要保存的是单个元素,而 Map 则可以将某些对象与其它一些对象存在的关系用 key-value 方式保存下来。接下来我们将就这两个部分展开分析。
Collection 接口
结构分析
这里为了方便分析只展示了接口的继承结构
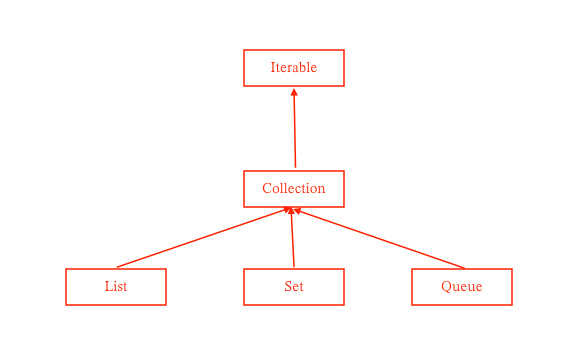
首先查看 Iterable
1 | public interface Iterable<T> { |
Itrable 接口中拥有一个 iterator 方法以及两个 1.8 添加的默认方法:
- iterator:返回一个迭代器用于遍历
- forEach:根据给定的 action 处理每个元素
- spliterator:提供了一个用于并行遍历的迭代器,由于这里主要探讨结构设计,所以暂且不展开说明
看到这里我产生了第一个疑问,为什么 Collection 不直接继承 Iterator 接口,而需要用 Iterable 进行包装之后再继承呢? 这里假设存在一个 CustomizeCollection 接口在包含了 Collection 接口方法的基础上继承了 Iterator 接口而不是 Iterable(或者是直接包含了 Collection 接口方法以及 Iterator 接口方法),那么当我们实现 CustomizeCollection 接口的时候所得到的 CustomizeClass 类结构将如下图所示:
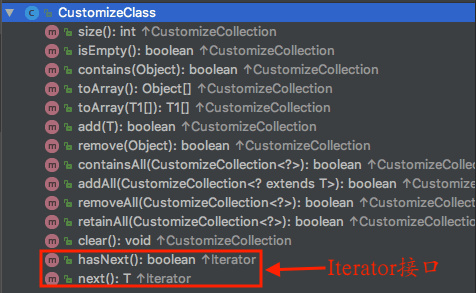 可以看到如果想实现 CustomizeCollection 则必须要实现 Iterator 接口方法,很显然采用这种方式可能导致在不同的 CustomizeCollection 接口实现类中存在相同的 Itrator 接口方法实现(遍历这一操作某些时候可能是通用的),这样一来就降低了代码的复用性,另外从单一职责的角度来考虑,CustomizeCollection 接口中揉合了集合元素的管理功能以及迭代器的功能,而采用 Iterable 包装之后则可以将这两个功能进行一定程度上的分割。
可以看到如果想实现 CustomizeCollection 则必须要实现 Iterator 接口方法,很显然采用这种方式可能导致在不同的 CustomizeCollection 接口实现类中存在相同的 Itrator 接口方法实现(遍历这一操作某些时候可能是通用的),这样一来就降低了代码的复用性,另外从单一职责的角度来考虑,CustomizeCollection 接口中揉合了集合元素的管理功能以及迭代器的功能,而采用 Iterable 包装之后则可以将这两个功能进行一定程度上的分割。
接着从 Collection 又延展出三个接口,这三个接口是对集合功能的具体化:
- Set 表示的是无序、不存在重复元素的集合
- List 表示的是一种有序、可重复元素的集合
- Queue 表示的是一种队列,其实队列也是一种有序的集合,但之所以会单独设计出一个接口的原因在于,Queue 接口去除了很多不需要的功能,使得接口本身更符合单一职责以及接口隔离原则。
功能分析
Collection 接口的功能大致概括如下(暂不介绍 1.8 引入的默认方法)
- 增加
- boolean add(E e) 增加单元元素
- boolean addAll(Collection<? extends E> c) 增加集合 c 的元素
- 删除
- boolean remove(Object o) 移除元素
- boolean removeAll(Collection<?> c) 移除集合 c 的元素
- void clear() 清空集合
- 查询
- boolean contains(Object o) 查询集合是否存在元素 o
- boolean containsAll(Collection<?> c)查询当前集合是否存在集合 c 中的所有元素
- boolean isEmpty() 查询是否集合为空
- int size() 查询集合的大小
- 其它
- Iterator
iterator() 返回迭代器 - boolean retainAll(Collection<?> c) 取当前集合和集合 c 的交集
- Iterator
Set 接口与 Colleciton 接口定义的方法完全一致
List 接口在 Collectiion 接口基础上新增了一些与索引有关的方法
- 增加
- void add(int index, E element) 在 index 处插入元素
- 删除
- E remove(int index) 删除 index 处的元素
- 修改
- E set(int index, E element) 修改 index 的元素为 element
- 查询
- E get(int index) 获取 index 处的元素
- int indexOf(Object o) 获取元素 o 第一次出现的 index
- int lastIndexOf(Object o) 获取元素 o 最后一次出现的 index
- 其它
- ListIterator
listIterator() 返回 ListIterator 类型的迭代器 - ListIterator
listIterator(int index) 返回从 index 开始的 ListIterator 类型的迭代器
- ListIterator
Queue 接口新增的方法如下
- 出队
- E peek() 出队但是不删除元素,在队列为空的时候返回 null
- E element() 出队但是不删除元素,在队列为空的时候抛出异常
- E poll() 出队并且删除元素,在队列为空的时候返回null
- E remove() 出队并且删除元素,在队列为空的时候抛出异常
- 入队
- boolean offer(E e)
Map 接口
结构分析
Map 是一个单一的接口,并没有在此基础上进行扩展,但在 Map 接口的内部有一个 Entry 接口:
1 | interface Entry<K,V> { |
可以看到 Entry 里面封装的都是和 Map 中元素有关的操作,这一接口主要用来规定 Map 中用来存储 key-value 所需要提供的功能
功能分析
Map 接口的功能大致如下:
- 增加或修改
- V put(K key, V value) 存储 key 和 value,如果 key 已经存在则会将原来的 value 替换为新的 value
- void putAll(Map<? extends K, ? extends V> m) 将 m 中的 key 和 value 添加到当前 Map 中
- 删除
- V remove(Object key) 移除指定的 key 以及关联的 value
- void clear() 清空 Map
- 查找
- V get(Object key) 获取 key 关联的 value
- boolean containsKey(Object key) 判断当前 Map 是否包含指定的 key
- boolean containsValue(Object value) 判断当前Map 是否包含指定的 value
- boolean isEmpty() 判断当前 Map 是否为空
- int size() 获取当前 Map 的大小
- 其它
- Set
keySet() 将 key 生成 Set 集合 - Collection
values() 将 value 生成集合 - Set<Map.Entry<K, V>> entrySet() 将 Map 中保存的元素生成 Set 集合,一般用于遍历集合
- Set
从 Map 接口所提供的方法来看,大部分方法其实与 Collection 接口中无异,只是在 Collection 中是对单个元素进行操作,但是在 Map 接口中是对 key-value 这种关联元素进行操作。
总结
Java 集合框架以 Colleciton 和 Map 为基础,高度抽象了对单个元素以及键值对的操作,而在此基础上为了减轻业务开发难度,集合框架又提供了多个实现类以供使用,尽管看起来错综复杂,但是只要了解核心的接口之间的继承关系便可对集合框架有个较为清晰的认识。