Python 下用 Scrapy 采集知网期刊数据(四)
在Python 下用 Scrapy 采集知网期刊数据(三)中采集了所需数据,接下来该进行的就是数据的存储和导出。
数据存储
- 创建 MySql 表


- 导入 pymysql 库
import pymysql - 配置 MySql 在
setting.py文件中写入下列配置代码:1
2
3
4
5
6# start MySQL database configure setting
MYSQL_HOST = 'localhost'
MYSQL_DBNAME = '数据库名'
MYSQL_USER = '登录名'
MYSQL_PASSWD = '密码'
# end of MySQL database configure setting 编写 item pipeline
每个 item pipeline 组件(有时称之为 “Item Pipeline” )是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以采集引证文献的 item pipeline 为例:
item pipeline 中需要判断 item 的类型是否是需要被处理的类型,进而进行查询判断该条记录是否在数据库中存在,如果存在则进行更新,否则进行插入。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46class CnkiPipeline(object):
def __init__(self):
self.connect = pymysql.connect(
host=settings.MYSQL_HOST,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8',
use_unicode=True)
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
if item.__class__ == Quote:
try:
self.cursor.execute("""select * from reference where literature_title = %s and quote_title = %s AND literature_author = %s
AND literature_journalName = %s AND literature_time = %s""",
(item["paper_title"], str(item['quote_title']), item['paper_author'],
item['paper_journalName'], item['paper_time']))
ret = self.cursor.fetchone()
if ret:
self.cursor.execute(
"""update reference set literature_title = %s,literature_author = %s, literature_journalName = %s,
literature_time = %s,quote_title = %s
where literature_title = %s and quote_title = %s AND literature_author = %s""",
(str(item['paper_title']),
str(item['paper_author']),
str(item['paper_journalName']),
str(item['paper_time']),
str(item['quote_title']),
str(item['paper_title']),
str(item['quote_title']),
str(item['paper_author'])))
else:
self.cursor.execute(
"""insert into reference(literature_title,literature_author,literature_journalName,
literature_time,quote_title)
value (%s,%s,%s,%s,%s)""",
(str(item['paper_title']),
str(item['paper_author']),
str(item['paper_journalName']),
str(item['paper_time']),
str(item['quote_title'])))
self.connect.commit()
except Exception as error:
log(error)
return item爬取结果


数据导出
为了将数据导出为 Excel 格式,利用到了xlrd,xlsxwriter,xlutils 库,导出代码如下:
1 | try: |
导出效果: 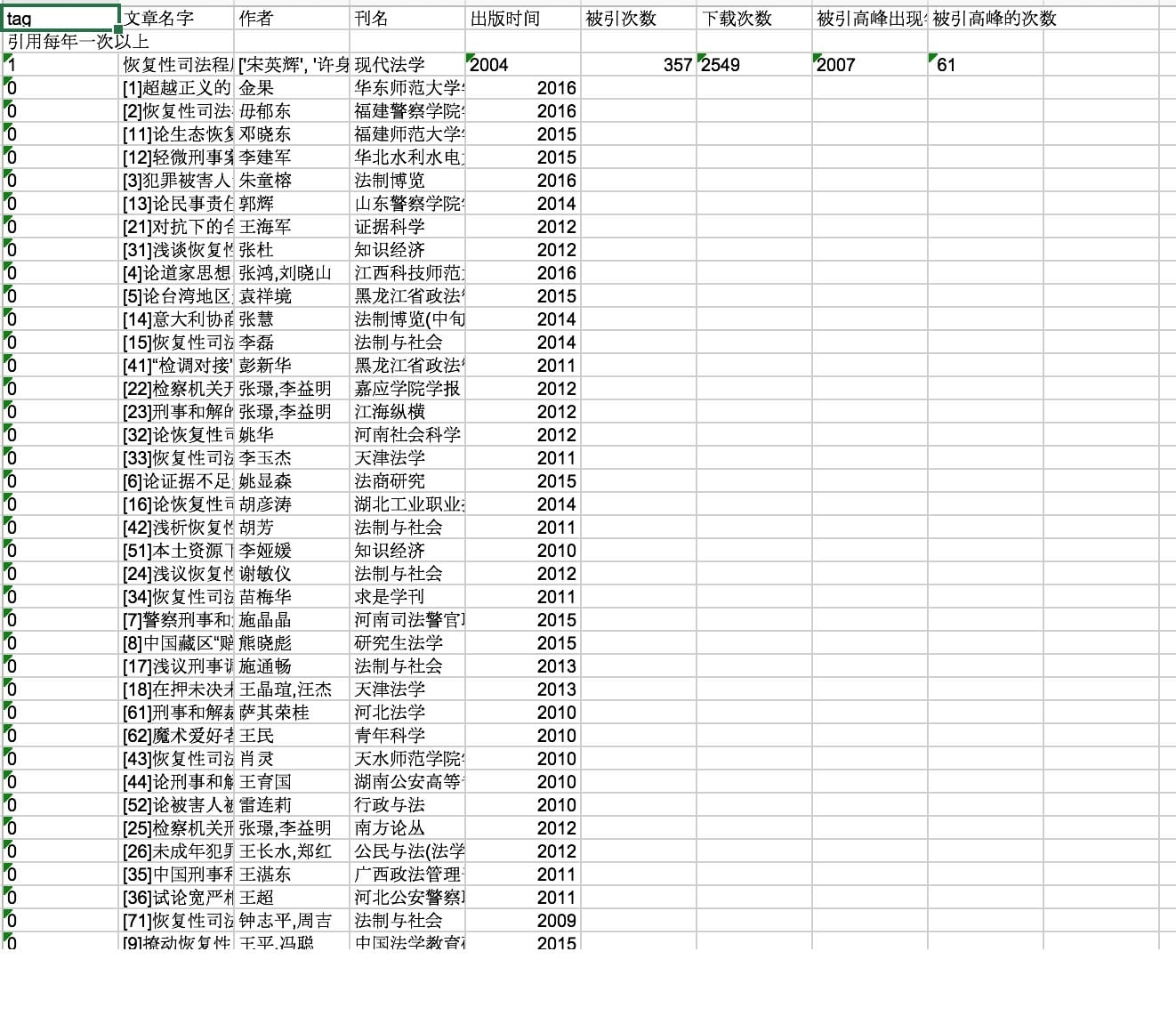
参考资料
Scrapy 文档