Python 下用 Scrapy 采集知网期刊数据(一)
简介
Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
安装
- Pycharm 安装 Mac 下按住快捷键
Command + ,选择 Project→Project Interpreter 点击 + 号后搜索 Scrapy 进行安装即可: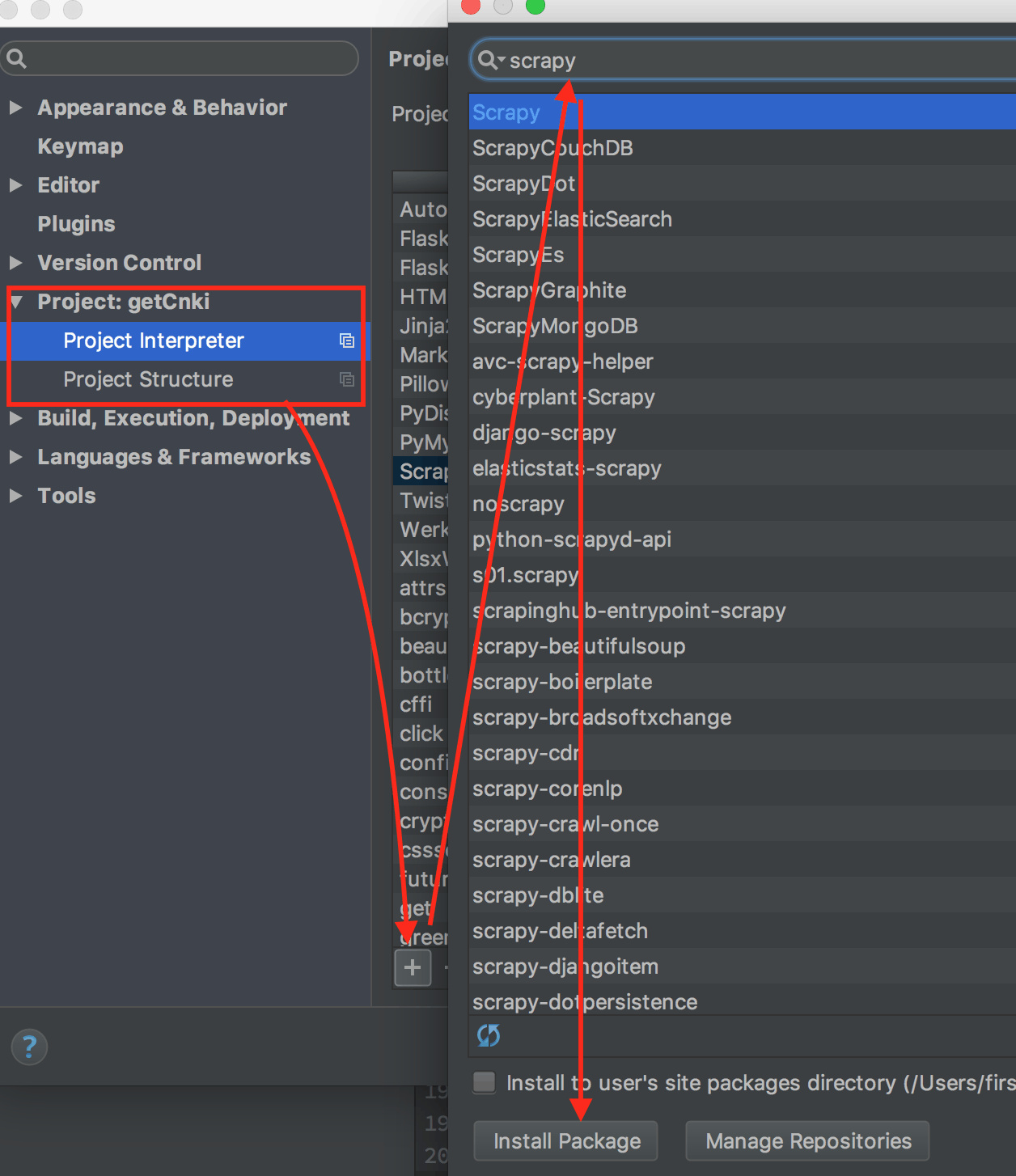
- pip安装
pip install Scrapy
创建工程
在终端中进入需要创建工程的目录,输入命令: scrapy startproject tutorial 将会创建一个 tutorial 的目录,目录结构如下:
1 | tutorial/ |
创建 Spider
在 tutorial/spiders 目录下新建一个名为 quotes_spider.py 的文件,输入如下代码:
1 | import scrapy |
QuotesSpider 继承 scrapy.Spider,同时定义了一些属性和方法: * name:作为爬虫的唯一标识,对于在同一工程中的爬虫,不能够设置相同的名称。 * start_requests():返回一个可迭代的请求,然后 Spider 将爬取这些请求 * parse():用于处理请求的结果。
运行 Sprider
- 终端命令运行 在创建的项目目录下,输入:
scrapy crawl quotesquotes 为 Sprider 的标识。 - Pycharm 下运行
在
tutorial目录下创建名为entrypoint.py的文件,输入如下代码:1
2
3
4#!/usr/bin/env python
from scrapy.cmdline import execute
# quotes 为刚刚创建的 Spider 的 name,可以在这里切换不同的 Spider
execute(['scrapy', 'crawl', 'quotes'])修改配置 在
Run中选择Edit Configurations,做如下修改:
参考资料
Scrapy 文档